Jolt Book | ePrint 2023/1217 | a16z, 2023 Authors: Arasu Arun, Srinath Setty, Justin Thaler
Jolt is a RISC-V zkVM built around sum-check and lookup arguments: Just One Lookup Table. As of v0.2.0, it uses Twist & Shout for memory checking / lookups, Spartan for R1CS, and Dory as the polynomial commitment scheme. It supports RV64IMAC.
Instruction Fetch (Bytecode)
Source: Jolt Book - Bytecode
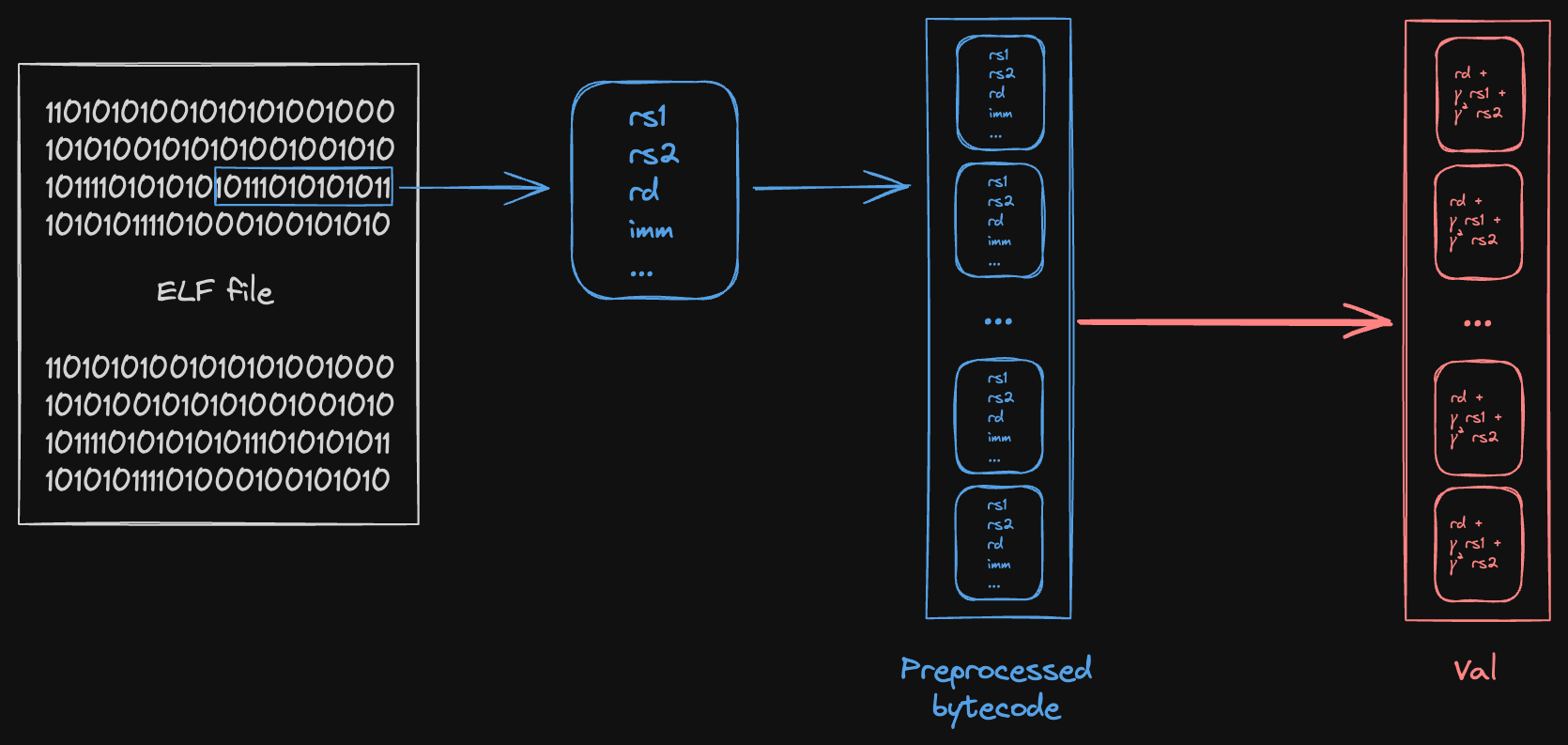
During preprocessing, the ELF binary is decoded into a table of instructions. Each entry is a tuple:
(rs1, rs2, rd, imm, circuit_flags, lookup_table_flags, address)
where:
- rs1, rs2: Source register indices (which of the 64 registers to read).
- rd: Destination register index (which register to write the result to).
- imm: Immediate value embedded in the instruction.
- address: The instruction’s ELF memory address (
unexpanded_pc). This is distinct from the bytecode index (its position in the preprocessed table). - circuit_flags: Booleans consumed by the R1CS constraints. They encode the instruction type for the constraint system. Examples:
jump_flag(JAL, JALR)branch_flagload_flag(LB, LW, …)add_operands(ADD, ADDI, AUIPC — instructions whose operands are added in the field)is_rd_not_zero,write_lookup_to_rdleft_is_rs1,left_is_pc,right_is_rs2,right_is_imm(which values to feed as the left/right operand)is_noop,virtual_instruction,is_first_in_sequence
- lookup_table_flags: Booleans that select which instruction lookup table to query during instruction execution (see below). There is one flag per supported instruction (e.g. one for XOR, one for AND, one for SLT, …).
At each cycle, the current PC indexes into this table to “fetch” the instruction. This is a read-only lookup, so it uses a Shout instance. The polynomial is a random linear combination of all the fields above, so that a single read-check proves the entire tuple at once.
Registers
Source: Jolt Book - Registers
Jolt has 64 registers (32 real RISC-V + 32 virtual):
| Registers | Purpose |
|---|---|
| 0–31 | Standard RISC-V registers (x0 hardwired to zero) |
| 32–33 | LR/SC reservation addresses (atomics) |
| 34–39 | M-mode Control and Status Registers (CSRs), handles traps |
| 40–46 | Temporaries for virtual instruction sequences |
| 47–63 | Temporaries for inline sequences |
Register read/write correctness is proven using Twist with and . Each cycle reads up to two source registers (rs1, rs2) and writes one destination (rd), so there are two polynomials and one polynomial, all batched into a single sum-check instance.
No separate one-hot checks for registers: Normally in Twist, the prover commits to polynomials and must prove they’re one-hot. For registers this is unnecessary: which register gets accessed is already determined by the instruction’s rs1/rs2/rd fields, and the bytecode Shout already proves those. So the register at a random point can be derived via a sum-check over the bytecode’s and the register index fields — no separate commitment or one-hot proof needed.
Instruction Execution
Source: Jolt Book - Instruction Execution
The key insight of Jolt: instruction execution is a single giant lookup. For each instruction, the two 64-bit operands form the lookup index, and the table returns the correct output. Their bits are interleaved:
This gives a table of size , which obviously cannot be materialized.
Prefix-Suffix Decomposition
The trick: for many instructions, the table’s MLE has prefix-suffix structure (Appendix A of Proving CPU Executions in Small Space). A multilinear polynomial has prefix-suffix structure for cutoff with terms if:
The prefix-suffix inner product protocol exploits this to run the sum-check (where is the sparse one-hot address) without ever materializing the -entry table. It proceeds in stages, each handling sum-check rounds:
- At each stage, the prover makes a single pass over the sparse to build a small array of size (aggregating suffix contributions).
- It builds a small array of size (prefix evaluations).
- The sum-check for those rounds reduces to an inner product , which is only -dimensional.
For this to work, must have prefix-suffix structure at every cutoff (not just one). The total prover cost is where is the sparsity of (= number of trace cycles ).
Example: SLT (Set Less Than)
SLT maps if , else . Recall the index is interleaved: . With a cutoff after 16 bits (8 bit-pairs), contains the high bits and the low bits .
The comparison decomposes as: iff the high bits of are less than those of , OR the high bits are equal and the low bits of are less than those of :
This is terms. Term 2 has non-trivial factors on both sides: whether the suffix matters is gated by the prefix bits being equal. This structure holds at every cutoff boundary (it’s the standard recursive definition of lexicographic comparison), so it works for any .
Example: XOR
XOR is a simpler case. Each output bit depends on a single input bit-pair independently: . So the decomposition is purely additive with no cross-boundary interaction:
where sums the weighted per-bit XORs for bits in the prefix, and does the same for the suffix. This is but both terms have a trivial factor (constant 1 on one side).
Multiplexing Between Instructions
Since different instructions have different tables, a boolean lookup table flag (fetched from the bytecode) indicates which table is active at cycle . The multiplexed read-checking sum-check becomes:
In practice, for instruction execution, giving (i.e., each of the 16 one-hot chunks has 256 entries). The sum-check degree per round is . Jolt uses techniques from Karatsuba/Toom-Cook to optimize the degree-17 polynomial evaluations.
Recovering Dense Operands (raf)
The R1CS constraints need the dense operand values (as field elements), not one-hot encodings. These are recovered via raf-evaluation sum-checks (see Twist and Shout, “Recovering dense addresses”]]). For two interleaved operands:
These extract the even-indexed bits (left operand ) and odd-indexed bits (right operand ) respectively. The resulting dense values are fed into the R1CS constraints for linking.
For instructions with a single operand (e.g., range checks), the index is not interleaved: the first 64 bits are zero-padded, and only RightOperand is non-trivial.
Committed Polynomials (according to Claude)
All committed polynomials are opened via Dory, which has “pay-per-bit” costs: boolean entries (the one-hot 1s) are much cheaper to commit than full field elements.
| Polynomial | Component | Hypercube size | Non-zero entries | Entry type |
|---|---|---|---|---|
| Instruction exec (Shout) | each | each (sparse) | Boolean | |
| Bytecode (Shout) | each | each (sparse) | Boolean | |
| RAM (Twist) | each | each (sparse) | Boolean | |
| Spartan (R1CS witness) | Dense | Field elements | ||
| Registers (Twist) | Dense | Field elements | ||
| Parameters: |
- Instruction execution: , . This is the largest commitment: boolean entries total.
- Bytecode: depends on program size (not a fixed constant).
- RAM: or depending on . Only (no separate ) since RV64IMAC does at most one memory operation per cycle.
- Spartan: is the number of R1CS variables per cycle (exact value unknown).
- Advice: Not separately committed polynomials. They are folded into the RAM initial state polynomial . “Trusted” advice has an externally-generated commitment; “untrusted” advice is committed by the prover. Both occupy the lowest addresses in the RAM table.
Uncertain / needs verification
- Register / : The register addresses are derived from bytecode (see “no separate one-hot checks” above). This suggests they are virtual (not committed), meaning the register Twist only commits to . But the docs are not fully explicit.
- RAM : The architecture overview lists it as committed, but the RAM-specific page describes it as virtual (proven through sum-checks). Unclear which is correct.
- RAM : With one memory op per cycle, there may be a single merged address polynomial rather than separate / .
TODO
- How Spartan R1CS glues the components (~20 constraints/cycle, PC updates, linking)
- RAM (Twist instance, memory layout, output verification)
- Virtual instructions (division decomposition, virtual registers 40-46)
- Inlines (custom instructions, SHA-256 benchmarks, virtual registers 47-63)
- The proof DAG: committed vs virtual polynomials, sum-check stages, where time is spent
- Interesting facts (e.g., d values per component)